
Project information
- Company: ORamaVR
- Categories: Data Engineering, MLOps, 3D Deep Learning
- Main technologies: Python, PyTorch, HuggingFace Datasets, Kaolin, Metaflow
Summary
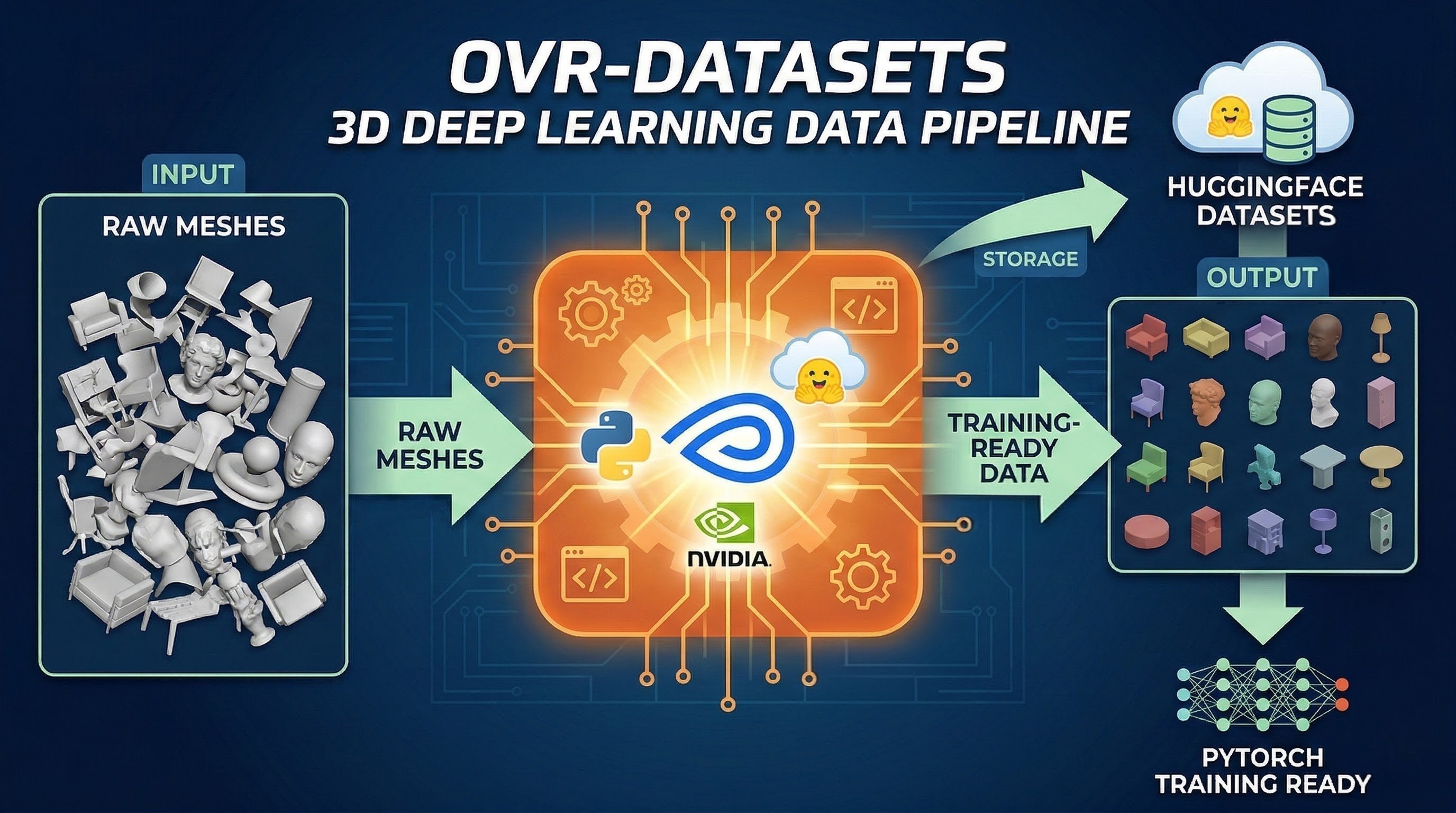
Training generative 3D models requires massive, well-structured datasets. OVR-Datasets was built as the foundational data engineering pipeline to handle 3D data at scale.
I developed an automated processing pipeline capable of standardizing and pre-processing millions of 3D meshes for deep learning workflows. A core feature of the project was creating a streamlined codebase to efficiently store, version, and retrieve these large-scale 3D datasets directly from HuggingFace.
By orchestrating the workflow with Metaflow and utilizing NVIDIA's Kaolin library for 3D operations, I ensured that massive datasets could be seamlessly and efficiently injected into heavy PyTorch training pipelines.